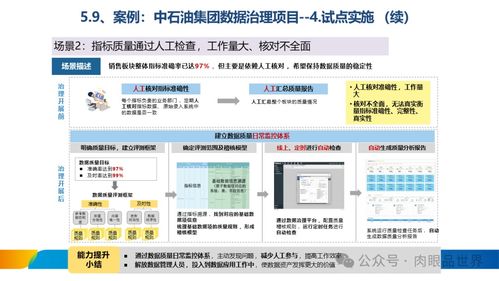
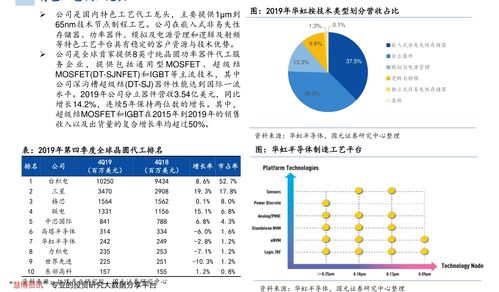
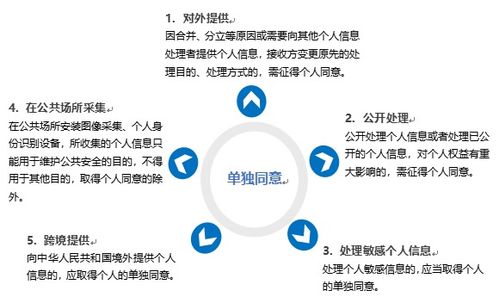
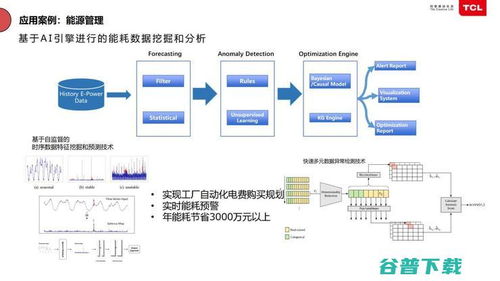
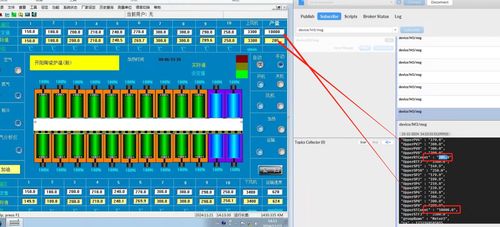
構建混合云無服務器數據倉庫 基于Amazon EMR Serverless、Athena、DolphinScheduler與本地TiDB、HDFS的集成實踐

在當今數據驅動的時代,企業面臨著數據處理敏捷性、成本效率與混合云架構兼容性的多重挑戰。傳統數據倉庫與數據處理流程往往依賴于固定的基礎設施,難以靈活應對波動的計算需求。本文將探討如何利用Amazon EMR Serverless、Amazon Athena、Apache DolphinScheduler,結合本地的TiDB數據庫與HDFS分布式文件系統,構建一個高效、彈性且成本優化的無服務器數據倉庫與數據處理服務。
一、 架構概覽與核心組件角色
本方案的核心思想是構建一個“混合部署、無服務器優先”的數據平臺,將云端強大的彈性計算與存儲能力,同本地數據源與特定服務相結合。
- 數據存儲層:
- 本地HDFS:作為原始數據、半結構化/非結構化數據的初始著陸區或歸檔層,尤其適用于對數據本地化有嚴格要求或網絡傳輸成本敏感的場景。
- 本地TiDB:作為需要強一致事務支持、低延遲查詢的在線業務數據庫(OLTP),同時其與MySQL協議兼容的特性,也使其成為數據集成的重要一環。
- Amazon S3:作為云端數據湖的核心存儲,通過連接器(如HDFS S3A Connector)或數據同步工具,可將HDFS數據高效同步至S3,為上層無服務器計算提供數據基礎。
- 無服務器計算與查詢層:
- Amazon EMR Serverless:這是數據處理的核心引擎。它允許用戶直接提交Spark、Hive等作業,而無需預置或管理集群。當需要運行ETL/ELT作業、復雜的數據轉換或機器學習任務時,可瞬間啟動任務,按實際計算資源消耗付費,任務完成后資源自動釋放,完美應對間歇性、不定時的數據處理需求。
- Amazon Athena:作為無服務器的交互式查詢服務,可直接使用標準SQL分析S3中的數據。它非常適合進行即席查詢、數據探查和生成報表。Athena的聯邦查詢功能甚至可以擴展至查詢本地TiDB等數據源(需通過Lambda連接器),實現跨云本地的統一SQL查詢界面。
- 統一調度與編排層:
- Apache DolphinScheduler:作為開源的分布式可視化工作流任務調度平臺,它是整個數據流水線的“中樞神經”。我們可以將其部署在本地或云端虛擬機,用于編排復雜的混合任務依賴關系,例如:
- 定時觸發HDFS到S3的數據同步任務。
- 編排EMR Serverless作業,處理S3中的數據并寫回。
- 調度對TiDB的數據抽取任務,并將結果寫入S3。
- 觸發Athena查詢任務,生成聚合表或業務報表。
- 監控所有任務的執行狀態與告警。
二、 關鍵集成與數據處理流程
一個典型的數據處理流程可能如下所示:
- 數據攝入與湖倉同步:
- 業務數據持續寫入本地TiDB,日志類數據寫入本地HDFS。
- DolphinScheduler調度數據同步任務(可使用Spark作業、Sqoop或定制腳本),定期將TiDB的增量數據、HDFS的新增文件同步至Amazon S3的數據湖中。
- 云端無服務器ETL處理:
- DolphinScheduler調用AWS SDK或API,提交一個EMR Serverless Spark作業。該作業讀取S3中的原始數據,進行清洗、轉換、聚合等操作,并將處理后的結構化數據以Parquet/ORC等列式格式寫回S3的特定路徑,形成“數據湖倉”的輕度匯總層或主題域層。
- 交互式查詢與分析:
- 數據分析師或業務系統通過Amazon Athena,直接使用SQL對S3中處理后的數據執行快速的即席查詢,生成業務洞察。
- 對于需要結合TiDB最新交易數據的查詢,可探索使用Athena Federated Query,通過預置的Lambda連接器將查詢下推至本地TiDB,在Athena中實現跨數據源的關聯分析。
- 結果反饋與數據應用:
- ETL處理后的聚合數據,可以再次由DolphinScheduler調度,回寫至本地TiDB(作為維度表或匯果),供低延遲的在線應用查詢。
- 也可將Athena的查詢結果直接對接可視化工具(如Amazon QuickSight、Tableau),形成固定報表或動態看板。
三、 核心優勢與價值
- 極致的成本優化:EMR Serverless和Athena均按掃描/計算的數據量付費,無閑置集群成本。配合S3的低成本存儲,實現了“用多少,付多少”的理想模型。
- 卓越的彈性與敏捷性:無需容量規劃,計算能力可瞬間從零擴展至PB級處理需求,輕松應對業務高峰與數據量增長。
- 混合架構的靈活性:既利用了云端無服務的先進能力,又保留了本地關鍵數據源與存儲,滿足數據合規、延遲和既有投資保護的要求。
- 運維簡化:無需管理Hadoop/Spark集群的運維、擴縮容、打補丁等復雜工作,團隊可更專注于數據邏輯與業務價值。
- 統一的調度管控:通過DolphinScheduler將云上與本地任務可視化編排,保障了端到端數據 pipeline 的可靠性、可監控性與可維護性。
四、 實施考量與挑戰
- 網絡與安全:需確保本地數據中心與AWS之間穩定、安全的網絡連接(如DX/VPN),并精細配置VPC、安全組、IAM角色與本地防火墻策略,以保障數據傳輸與API調用的安全。
- 數據同步延遲:需根據業務對數據新鮮度的要求,合理設計從TiDB/HDFS到S3的同步頻率與策略(全量/增量)。
- 元數據與權限統一:建議使用AWS Glue Data Catalog作為S3數據的中央元數據存儲,并與Athena、EMR Serverless無縫集成。權限管理需統籌考慮IAM、本地數據庫賬號及HDFS權限。
- 本地調度器高可用:為確保DolphinScheduler自身的高可用性,建議采用其主從或多活部署模式。
###
通過整合Amazon EMR Serverless與Athena提供的無服務器計算能力,Apache DolphinScheduler的強健編排能力,以及本地TiDB與HDFS的存儲與事務能力,企業可以構建一個高度彈性、成本可控且適應混合云環境的現代數據倉庫與處理服務。這種架構不僅降低了技術復雜度與運維負擔,更賦予了數據團隊快速響應業務變化、探索數據價值的強大能力,是傳統數據架構向云原生、智能化演進的重要路徑。
如若轉載,請注明出處:http://www.slysq.cn/product/42.html
更新時間:2026-02-23 15:01:05